풀이
[문제 풀이]
이 문제는 풀이를 잘 생각해 구현하면 되는 문제다.
단, 크기가 300000이기 때문에 O(n^2)의 시간복잡도로는 해결할 수 없다.
그러므로 누적합을 활용해 O(n)의 시간복잡도로 문제를 해결했다.
"aabba" 와 같은 문자열이 있다고 생각하자
이제 문자를 크게 두개로 나눠서 생각을 한다.
1. 양 끝 문자가 다른 경우
이 경우는 항상 문자열의 크기만큼의 아름다움을 갖게 된다.
2. 양 끝 문자가 같은 경우
이 경우는 양 끝 문자를 사이에 가장 아름다움을 갖는 문자를 찾아야 한다.
이제 아래와 그림을 보자
첫 문자 a부터 왼쪽으로 탐색을 시작한다.


탐색을 하다가 현재 문자가 b인데, 이전 문자가 a가 됐다.
그러므로 a의 값을 갱신해 준다.
a는 0번 index문자부터 마지막으로 연속했던 1번 index까지 탐색했을 때, 다른 문자가 없었으므로 다른 문자의 개수는 0이고 다른 문자로 인해 생긴 아름다움도 0이다
하지만 같은 문자는 0번 index와 1번 index 2개가 있었으므로 이를 갱신해 준다.
이 값을 갱신한 다음 b를 기준으로 아름다움을 계산해야 한다.
이때 b는 이번에 처음 나온 문자이므로 이전에 문자 b가 나온적이 없다는 사실을 알 수 있다.
이를 이용하면 b로 만들 수 있는 아름다움은 2+1임을 알 수 있다.
(만약 b가 10번째에서 처음 나왔다면 9+8+7+...+1 처럼 누적합으로 표현 할 수 있다.)

이를 이용하면 b까지 탐색했을 때 아름다움은 3이 된다.
다음 문자로 넘어가서 탐색을 시작하자

이전 문자와 현재 문자가 b로 같으므로 값을 갱신하지 않고, b는 여전히 처음 나왔다고 생각한다.
여기서 연속으로 몇 번 나왔는지를 체크해 주어야 하는데, 왜냐하면 연속으로 나온 횟수만큼 누적합에서 빼주어야 하기 때문이다.
즉, 앞에 3개의 문자가 있는데 하나의 문자는 b로 같은 문자라 아름다움이 0이다.
이를 누적합의 뺄셈으로 (3+2+1) - (1)로 표현해 빠르게 계산할 수 있다.
(앞서 말했지만, 빠르게 계산하기 위해서 누적합을 이용하는 것이다)
이제 마지막 문자 a까지 추가해보자.

마지막 문자 a는 앞의 문자 b와 다르다.
그러므로 b의 정보를 갱신한다.
b는 다른문자가 앞에 2개 있었고, 같은 문자가 2개 있었다.
그리고 마지막으로 나온 b (3번 index) 기준으로 다른문자로 만든 아름다움은 5다.
이러한 정보를 저장한 다음 a를 기준으로 아름다움을 계산한다.
a에는 앞에 a가 나온적이 있기 때문에 정보가 저장되어 있다.

다른 문자로 만들 수 있는 누적합이 0이고, 개수도 0이다.
그리고 마지막으로 a가 나온 index가 1이었다.
이를 이용하면 2~3번 index는 a와 다른 문자라는 사실을 알 수 있다.
4번 index 기준으로 2, 3 index는 아름다움의 합이 (2+1)이다.
그리고 같은 문자가 앞에 2개 연속으로 나왔다는 정보도 저장되어있다.
연속으로 몇 개 나왔는지 저장된 정보를 어떻게 이용할 수 있을까?

위 그림은 a가 연속으로 앞에 3개 나왔을 경우다.
맨 앞의 a와 만들 수 있는 아름다움은 3, 2번째 a와는 2이다.
3번째 a와 만들 수 있는 아름다움은 맨 뒤와 b로 1이라는 아름다움을 만들 수 있다.

이제 a가 하나 더 추가됐다고 생각해보자
여기서는 3, 2, 2의 아름다움을 갖게 된다는 점을 알 수 있다.
여기서 규칙을 알 수 있는데, 현재 연속된 문자의 수와 이전에 연속된 문자가 몇개 있는지 알고 있다면, 곱셈과 덧셈으로 빠르게 계산을 할 수 있다.
ex) 누적합 (3+2+1) - 누적합 (2+1) + 2 (거리) * 2 (연속한 a의 개수)
이제 다시 aabba로 문자로 돌아가면

(3+2+1) - (2+1) + 2 (거리) * 1(연속한 a의 개수) = 5로 마지막 a를 기준으로 같은 문자로 만들 수 있는 아름다움은 5 라는 사실을 알 수 있다.
지금까지 구한 아름다움을 모두 더하면 0+0+3+5+(5+3)=16이 된다.
마지막으로 아래와 같은 경우도 위치를 이동해 계산을 줄일 수 있다.
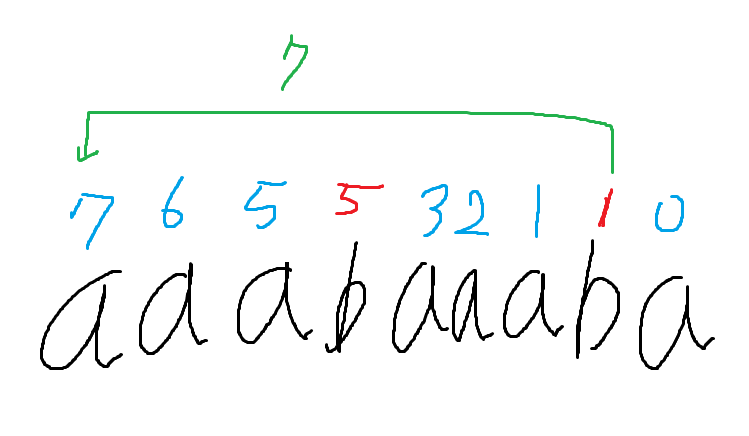
와 같은 문자에서 맨 앞에 aaa를 뒤로 4칸 이동하면

a 3개를 4칸 옮겼으므로 12만큼 값을 더한 것과 같다.
이를 이용하면 연속으로 이어진 문자가 몇 번 나왔는지를 이용해 곱셈으로 빠르게 계산할 수 있게 된다.
[아이디어 정리]
코드에 주석을 달아뒀으므로, 코드를 따라서 그려보며 이해하는 걸 추천합니다.
Code
#include <string>
#include <vector>
#include <algorithm>
#include <cmath>
#include <map>
using namespace std;
struct node
{
long long samePoint=0; //추가해줘야하는 누적 포인트
long long difPoint=0; //추가해줘야하는 누적 포인트
long long sameCnt=0;
long long difCnt=0;
int ed=0;
};
long long solution(string s) {
long long answer = 0;
char prevChar=s[0];
vector<bool> isFirst(26,false);
vector<long long> nuHap(300001,0); //1~i까지 누적 합
map<int, map<int, int>> sMap; //alpha : [길이 : 개수]
vector<node> nodeInfo(26);
int conCnt=1; //연속으로 몇 개 나왔는지
for (int i=1; i<s.length(); i++)
{
nuHap[i]=nuHap[i-1]+i;
int prevAlpha=prevChar-'a';
int prevI=i-1;
if (prevChar==s[i]) // 이전 문자와 현재 문자가 같다면
{
conCnt+=1;
}
else //다르다면 갱신해주면 됨
{
if (!isFirst[prevAlpha]) //처음이라면
{
isFirst[prevAlpha]=true;
nodeInfo[prevAlpha].difPoint=nuHap[prevI]-nuHap[conCnt-1];
nodeInfo[prevAlpha].sameCnt=conCnt;
nodeInfo[prevAlpha].difCnt=prevI-conCnt+1;
nodeInfo[prevAlpha].ed=prevI;
sMap[prevAlpha][conCnt]+=1;
}
else
{
// 처음이 아니라면
int eed=nodeInfo[prevAlpha].ed;
// 다른 알파벳들의 point 갱신
nodeInfo[prevAlpha].difPoint+=(prevI-eed)*nodeInfo[prevAlpha].difCnt+nuHap[prevI-eed-1]-nuHap[conCnt-1];
// 같은 알파벳들의 point 갱신 필요
nodeInfo[prevAlpha].samePoint+=(prevI-eed)*nodeInfo[prevAlpha].sameCnt;
sMap[prevAlpha][conCnt]+=1;
nodeInfo[prevAlpha].sameCnt+=conCnt;
nodeInfo[prevAlpha].difCnt=prevI+1-nodeInfo[prevAlpha].sameCnt;
nodeInfo[prevAlpha].ed=prevI;
}
prevChar=s[i];
conCnt=1;
}
// 계산 할 차례
int nowAlpha=s[i]-'a';
long long ccct=0;
// 다른 문자 점수
int eed=nodeInfo[nowAlpha].ed;
// 이전 정보로 가져오고
if (!isFirst[nowAlpha])// 방문 전이였다면
{
ccct=nuHap[i]-nuHap[conCnt-1];
}
else
{
ccct+=nodeInfo[nowAlpha].difPoint+(i-eed)*nodeInfo[nowAlpha].difCnt;
ccct+=nuHap[i-eed-1]-nuHap[conCnt-1];
}
// 그 사이에 있는 문자도 다르므로 더해주기
// 같은 문자 점수는 Map을 활용해 빠르게 계산
for (map<int, int>::iterator it=sMap[nowAlpha].begin(); it!=sMap[nowAlpha].end(); it++)
{
pair<int, int> np =*it; //first 길이, second 개수
if (conCnt<np.first)
{
//기본 유리 고쳐야함
ccct+=(nuHap[(i-conCnt)-(eed-np.first+1)]-nuHap[i-(eed+1)])*np.second;
}
// 유리한 거리로 더하기
ccct+=(i-(eed+1))*np.second*min(conCnt, np.first);
}
ccct+=nodeInfo[nowAlpha].samePoint; // 같은 알파벳 이동 포인트만큼 더해주기
answer+=ccct;
}
return answer;
}
아이디어는 빠르게 생각났는데, 실제로 구현하는데 시간이 오래 걸렸다...
식을 쓸 종이를 깜빡해서 야금야금 풀다보니 계속 문제가 생겨 코드를 싹 밀고 처음부터 풀었다;;
어우 당분간 어려운 문제는 패스해야겠다...
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
'Algorithm > 프로그래머스' 카테고리의 다른 글
| [프로그래머스/C++] [1차] 다트 게임 (2018 KAKAO BLIND RECRUITMENT) (0) | 2024.04.05 |
|---|---|
| [프로그래머스/C++] 후보키 (2019 KAKAO BLIND RECRUITMENT) (0) | 2024.04.04 |
| [프로그래머스/C++] 빛의 경로 사이클 (0) | 2024.04.01 |
| [프로그래머스/C++] 3 x n 타일링 (0) | 2024.03.31 |
| [프로그래머스/C++] 브라이언의 고민 (2017 카카오코드 예선) (0) | 2024.03.30 |